Kafka- Best practices & Lessons Learned | By Inder
As of December 2021, I have spent almost 3 years managing kafka (both self managed and AWS MSK) for BFSI Clients. I have also migrated kafka clusters from self managed to AWS managed kafka using mirror maker in production with zero downtime, which i will explain in my next post.
In this post, I want to share some of my best practices and lessons learned from using Kafka.
Here are 7 specific tips to keep your Kafka deployment optimized and more easily managed:
- Kafka hardware requirements
- Broker configurations
- Producer configurations
- Kafka Security (TLS)--encryption reduces performance by 30%(approx)
- Capacity of cluster
- Monitoring and alerting (esp consumer lag)
- DR/HA Setup
Know Kafka hardware requirements
CPU
Most Kafka deployments tend to be rather light on CPU requirements. But there are some factors which can increase CPU utilization of kafka broker.
- If SSL is enabled, the CPU requirements can be significantly higher (the exact details depend on the CPU type and JVM implementation).
- A higher replication factor consumes more disk and CPU to handle additional requests.
- If compression is used, then producers and consumers must commit some CPU cycles for compressing data and decompressing data. More cores also lead to more parallelization.
Memory
Kafka brokers use both the JVM heap and the OS page cache. The JVM heap is used for replication of partitions between brokers and for log compaction. It is highly recommended that consumers always read from memory, i.e. from data that was written to Kafka and is still stored in the OS page cache. The amount of memory this requires depends on the rate at this data is written and how far behind you expect consumers to get. If you write 20GB per hour per broker and you allow brokers to fall 3 hours behind in normal scenario, you will want to reserve 60GB to the OS page cache. In cases where consumers are forced to read from disk, performance will drop significantly.
Kafka uses page cache memory as a buffer for active writers and readers, so after you specify JVM size (using -Xmx and -Xms Java options), leave the remaining RAM available to the operating system for page caching.
In most cases, Kafka can run optimally with 6 GB of RAM for heap space. For especially heavy production loads, use machines with 32 GB or more. Extra RAM will be used to bolster OS page cache and improve client throughput. While Kafka can run with less RAM, its ability to handle load is hampered when less memory is available.
For sustained, high-throughput brokers, provision sufficient memory to avoid reading from the disk subsystem. Partition data should be served directly from the operating system’s file system cache whenever possible. However, this means you’ll have to ensure your consumers can keep up; a lagging consumer will force the broker to read from disk.
Broker Configuration
Kafka topic configuration
Topic configurations have a tremendous impact on the performance of Kafka clusters. Because alterations to settings such as replication factor or partition count can be challenging, you’ll want to set these configurations the right way the first time, and then simply create a new topic if changes are required (always be sure to test out new topics in a staging environment).
Use a replication factor of three and be thoughtful with the handling of large messages. Partition count is a critically important setting as well, discussed in detail in the next section.
The topic configurations have a ‘server default’ property. These can be overridden at the point of topic creation or at later time in order to have topic-specific configuration.
Either disable automatic topic creation or establish a clear policy regarding the cleanup of unused topics. For example, if no messages are seen for x days, consider the topic defunct and remove it from the cluster. This will avoid the creation of additional metadata within the cluster that you’ll have to manage.
Use parallel processing
Topic/Partition is unit of parallelism in Kafka. As it is designed for parallel processing and, like the act of parallelization itself, fully utilizing it requires a balancing act. Partition count is a topic-level setting, and the more partitions the greater parallelization and throughput. However, partitions also mean more replication latency, rebalances, and open server files.
Finding your optimal partition settings is as simple as calculating the throughput you wish to achieve for your hardware, and then doing the math to find the number of partitions needed.
Method to find number of partitions.
Method 1
- Lets call the throughput from producer to a single partition is P
- Throughput from a single partition to a consumer is C
- Target throughput is T
- Required partitions = Max (T/P, T/C)
Partitions = Desired Throughput / Partition Speed

How to compute your throughput
It might also be helpful to compute the throughput. For example, if you have 800 messages per second, of 500 bytes each then your throughput is 800*500/(1024*1024) = ~0.4MB/s. Now if your topic is partitioned and you have 3 brokers up and running with 3 replicas that would lead to 0.4/3*3=0.4MB/s per broker.
Method 2
Let’s get straight into testing is to use one partition per broker per topic, and then to check the results and double the partitions if more throughput is needed.
Production recommendations
Overall, a useful rule here is to aim to keep total partitions for a topic below 10, and to keep total partitions for the cluster below 10,000. If you don’t, your monitoring must be highly capable and ready to take on what can be very challenging rebalances and outages!
More partitions can increase the latency. The end-to-end latency in Kafka is defined by the time from when a message is published by the producer to when the message is read by the consumer. Kafka only exposes a message to a consumer after it has been committed, i.e., when the message is replicated to all the in-sync replicas. Replication 1000 partitions from one broker to another can take up 20ms. This can be too high for some real-time applications. In new Kafka producer , messages will be accumulated on the producer side. It allows users to set upper bound on the amount of memory used for buffering incoming messages. Internally, producers buffers the message per partition. After enough data has been accumulated or enough time has passed, the accumulated messages will be removed and sent to the broker.If we have more partitions , messages will be accumulated for more partitions on producer side.Similarly on the consumer side , it fetches batch of messages per partitions . The more partitions that consumer is subscribing to, the more memory it needs.
The partition count can be increased after creation. But it can impact the consumers, so it’s recommended to perform this operation after addressing all consequences.
Number of replicas
We generally use 3x replication in our production environments to protect data in situations when up to two brokers are unavailable at the same time. However, in situations where achieving higher throughput and low latency is more critical than availability, the replication factor may be set to a lower value.
Partitions density
Kafka can handle thousands of partitions per broker. The throughput will decline for higher partition density corresponds to the high latency, which was caused by the overhead of additional I/O requests that the disks had to handle.
Also, keep in mind that increasing partition density may cause topic unavailability. In such cases, Kafka requires each broker to store and become the leader to a higher number of partitions. In the event of an unclean shutdown of such brokers, electing new leaders can take several seconds, significantly impacting performance.
Producer Configurations
Producer required acks — Configure your producer to wait for acknowledgments
Producer required acks configuration determines the number of acknowledgments required by the partition leader before a write request is considered completed. This setting affects data reliability and it takes values 0, 1, or -1 (i.e. “all”).
To achieve highest reliability, setting acks = all guarantees that the leader waits for all in-sync replicas (ISR) to acknowledge the message. In this case, if the number of in-sync replicas is less than the configured min.insync.replicas, the request will fail. For example, with min.insync.replicas set to 1, the leader will successfully acknowledge the request if there is at least one ISR available for that partition. On the other end of the spectrum, setting acks = 0 means that the request is considered complete as soon as it is sent out by producer. Setting acks = 1 guarantees that the leader has received the message.While ack = -1 provides stronger guarantees against data loss, it results in higher latency and lower throughput. Value of ack provides Intuitive tradeoff that arises between reliability guarantees and latency.
For high-throughput producers, tune Batch size
Each Kafka producer batches records for a single partition, optimizing network and IO requests issued to a partition leader. Therefore, increasing batch size could result in higher throughput. Under light load, this may increase Kafka send latency since the producer waits for a batch to be ready. For example, we put our producers under a heavy load of requests and thus don’t observe any increased latency up to a batch size of 512 KB. Beyond that, throughput dropped, and latency started to increase. This means that our load was sufficient to fill up 512 KB producer batches quickly enough. But producers took a longer time to fill larger batches. Therefore, under heavy load it is recommended to increase the batch size to improve throughput and latency.
Compression
A Kafka producer can be configured to compress messages before sending them to brokers. The Compression.type setting specifies the compression codec to be used. Supported compression codecs are “gzip,” “snappy,” and “lz4.” Compression is beneficial and should be considered if there is a limitation on disk capacity.
Configure Kafka with security in mind
Security does carry a cost to throughput and performance, it effectively and valuably isolates and secures traffic to Kafka brokers.
Kafka Security has three components:
- Encryption of data in-flight using SSL / TLS: This allows your data to be encrypted between your producers and Kafka and your consumers and Kafka. This is a very common pattern everyone has used when going on the web. That’s the “S” of HTTPS (that beautiful green lock you see everywhere on the web).
- Authentication using SSL or SASL: This allows your producers and your consumers to authenticate to your Kafka cluster, which verifies their identity. It’s also a secure way to enable your clients to endorse an identity. Why would you want that? Well, for authorization!
- Authorization using ACLs: Once your clients are authenticated, your Kafka brokers can run them against access control lists (ACL) to determine whether or not a particular client would be authorised to write or read to some topic.
What should the capacity of my kafka cluster be?
Kafka stores data for each partition on a log, and logs are further divided into log segments. Kafka determines how long to store data based on topic-level and segment-level log retention periods.
The answer depends on the configuration of these functions:
- the topic’s retention period
- the average size of your Kafka messages
- the amount of messages you expect to push through the system.
- replication factor
Data retention is particularly important in Kafka because messages remain in topics, taking up disk space on the brokers until their configurable size is reached or the retention period elapses. These messages remain even if they have already been consumed. If the data retention period or size is set too low, the data may not be consumed before it is removed from the broker.
Monitoring & Alerting
Three very important things to monitor and alert on for Kafka clusters:
- Retention: How much data could be stored on disk for each topic partition?
- Replication: How many copies of the data could be made?
- Consumer Lag: How to monitor how far behind our consumer applications are from the producers?
- Monitoring system metrics such as network throughput, open file handles, memory, load, disk usage, and other factors — is essential, as is keeping an eye on JVM stats, including GC pauses and heap usage.
Disaster Recovery Plan
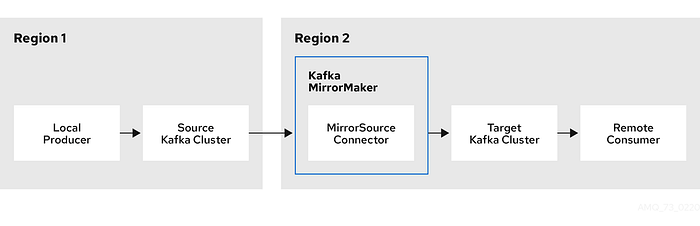
A disaster recovery plan is critical for all of your services, and Kafka is no exception. Kafka has a featured called MirrorMaker2 that lets you consume data from one cluster and copy it to another, retaining data for disaster recovery purposes.”. In this situation, Kafka consumers and producers can be switched to using the mirrored cluster if the main Kafka cluster goes down.
uReplicator from Uber can be used for DR. But it uses Apache Helix that requires additional domain knowledge and maintenance.
Confluent Replicator should be a better solution, but it is a proprietary and enterprise software.
Key Takeways
- Low overhead and horizontal-scaling-friendly design of Kafka makes it possible to use inexpensive commodity hardware and still run it quite successfully.
- For sustained, high-throughput brokers, provision sufficient memory to avoid reading from the disk subsystem.
- More partitions mean a greater parallelization and throughput but partitions also mean more replication latency, rebalances, and open server files.
- Increase Kafka’s default replication factor to three, which is appropriate in most production environments.
- Monitor consumer lag.
